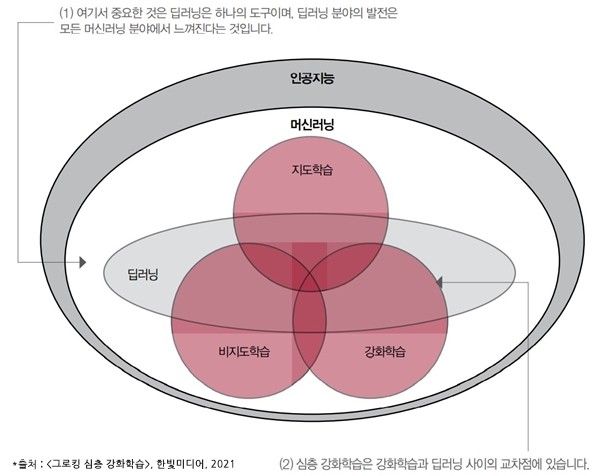
사람은 태어나서 부모와 가족, 사회에서 지도 학습, 강화 학습, 비 지도 학습의 각 부분이 균등하게 적용되지만 가끔 이상한 환경에 처한다면 한가지 학습 법이 특히 많아지는 경우도 있다.일반적으로 시행 착오에서 배우고 경험이 누적된 시행 착오를 줄이는 방법이 가지만 경험의 누적에는 책과 미디어, 대화 등을 통한 간접 경험의 누적으로 보다 빠른 경험 축적을 추구한다.이처럼 Explore(탐색에 의한 경험의 축적)와 Exploit(경험의 활용)에서 행동이 우아할 보수화된다. 이것의 기반은 결국 보상으로 칭찬이나 보수, 도움 등 때문에 정제된 행위로 만들기.강화 학습은 지도 학습과 비 지도 학습의 중간 정도의 어딘가에 있는 학습 법으로 우리의 학습 법과 매우 흡사하다.강화 학습은 현재 상태(State)에서 어떤 행동(Action)을 취하는 것이 최적화를 학습함으로써 한마디로 정의하면 시행 착오와 배우는 경험을 쌓고 시행 착오를 줄인다.
행동을 취할 때마다 외부 환경에서 보상(Reward)이 주어지며, 이 보상을 극대화하는 방향으로 학습을 한다.예를 들어 사람(Agent)은 이 세상(Environment)을 살아가는 매 순간(State)마다 어떤 결정(Decision)을 하고 행동(Action)을 해야 하는데, 그 행위(Action)는 보상(Reward)을 세상(Environment)으로 받음으로써 동물이 먹이를 얻을 수 있는 방법으로 행동이 변하도록 경험이 축적된다.
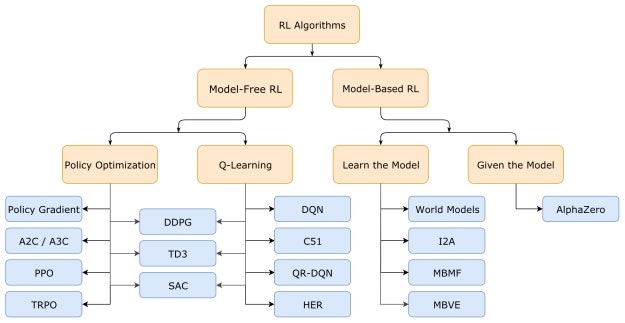
아기가 걷는 법을 배우는 과정을 예로 들면 아기(agent)는 부모(환경)의 칭찬(보상:reward)을 받으며 다리를 비틀거리며 움직이며(action) 서실 수를 줄이는 행위를 누적하면서 나중에 걷게 된다.강화학습(Reinforcement Learning:RL)은 Q-Learning이 유명한데, Q-Learning은 무작위 행동 빈도를 낮추면서 세상이 주는 보상에 대한 경험을 쌓아 세상의 다양한 형태에 대응할 수 있는 가장 올바른 행동양식을 찾아가는 학습방법이며, Q Value는 특정 상태에서 액션을 수행했을 때 기대되는 보상의 합으로 보상의 최대치를 따른다. Q-Learning을 딥러닝에 적용한 DQN은 초기에는 큰 인기를 얻었으나 이러한 Q-Learning의 위치는 아래 트리에서 확인하자.
")




2013년 1~3월 영국 딥마인드는 구글에 인수되기 전 강화학습을 이용한 게임 논문을 발표한다.논문 제목이 playing atari with deeprein forcement learning이라는 https://www.youtube.com/embed/V1eYniJ0Rnk 가 논문 이후 강화학습이 많아 인기를 끌면서 많은 기업이 개발에 돌입하지만 딥마인드는 이후 구글에 인수돼 DQN보다 성능 좋은 A3C를 발표한다.

더 자세한 내용은 UCBerkeley강의 자료를 참조한다:http://rail.eecs.berkeley.edu/deeprlcourse/요즘은 DQN보다 A3C나 PolicyGradient방식이 인기가 높은 것으로 알려졌다. A3C(Asynchronous Advantage Actor-Critic)알고리즘은 Replay Memory대신 다양한 에이전트(Agent)를 비동기식(Asynchronous)에서 동시에 학습시킴으로써 학습 속도를 높인 것이다. 이처럼 CNN을 적용한 DQN은 게임을 아주 잘하고 사람에게 이기기도 하지만 하늘색 DQN은 회색의 사람 플레이어보다 우수한 게임이 많다.

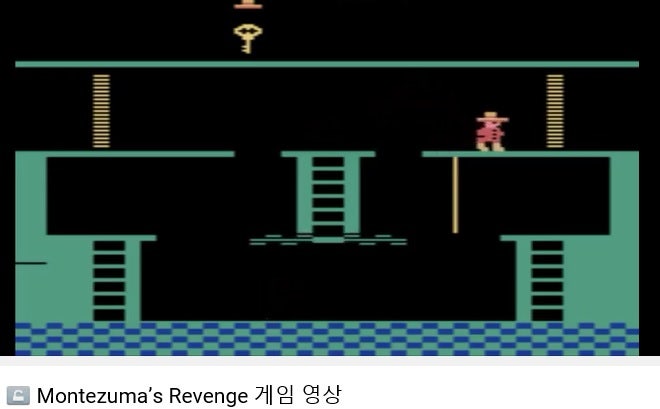
특히 브레이크아웃과 같은 비디오 게임은 사람을 완전히 추월하지만 맨 아래 몬테주마의 레전드 게임은 DQN 학습이 0%라는 전혀 학습하지 못하고 있다.즉 이 게임이 다른 게임에 비해 게임 복잡도가 상당히 높다는 것으로 A3C에서는 조금 있다.

이러니 지금의 상용 게임인 스타 크래프트 같은 것을 처리하기 위해서는 연구가 더 필요하게 되는 일이 쉽게 예측된다.현재 AIIDE, CIG, SSCAIT가 세계 3대 스타 크래프트 AI대회로 알려졌지만 8명으로 구성된 삼성 SDS의 SAIDA팀이 2018년 11월 AIIDE스타 크래프트 AI대회에서 우승했다.한국 엔지니어들도 상당한 실력이다. 대단하다. 어쨌든 딥 러닝이 게임을 배우는 방식이 사람들이 게임을 배우는 방식보다 난이도가 높으면서 사람은 게임 설명서를 보지만 딥-러닝은 단지 영상만 제공되며 규칙은 시행 착오로 스스로 찾다.이런 강화 학습의 좋은 점은 무엇보다 다른 학습에서 요구되는 데이터나 라벨이 적은 요구되며, 기계가 스스로 시행 착오로 학습을 찾겠다는 것이다.그래서 로봇을 걸게 하거나 자동 운전, 자연 언어 처리, 게임 등에 사용되는 기술로서 정착했다. 이쯤에서 강화 학습이 시작되는 간단한 이론부터 살펴보자.에이전트(예컨대 사람이나 캐릭터가 행동하고 보수를 얻으면 행동은 환경의 변화를 창출하면 에이전트는 다시 새로운 행동을 해야 하는 상황의 반복이 되지만 결국 보수를 더 얻기 위한 행동의 결정이 중요하다.다음 행동을 선택하는 방법에 대한 규칙을 정책(policy)라고 하는데 집값이 급등하면 종합 부동산세를 올리고 집값을 잡겠다는 정책 수립의 같은 것이다.이런 상황을 정형화하면 어느 상태가 있는 행동이 있을 수 있으므로, 상태와 행동으로 도표를 구성할 수 있다.그리고 한 상태에서 다음 상태로 바뀔 때 보상이라는 과정이 첨가되면 좋다.다만, 다음의 상태의 확률은 현재의 상태와 현재 행동에 의해서만 영향을 받아 과거의 영향을 배제시킨 규정을 적용하고 완성하면 마르코프 결정 과정이 완성된다.

상태 변화는 확률이 결정하고 상태 변화는 정해진 행동을 해야 하고 이때 누적 보상이 최고가 되는 행동 절차를 스스로 찾아 상태 변화를 지속하기에 확률이 0%가 되면 그 상태 변화 연결은 끊어진 것이다. 에이전트가 확률적 환경 안에서는 같은 행동을 해도 같은 보상을 받을지도 모르는 상황이 나오는 것으로 바로 보상과 미래 보상의 가치를 달리하고 긴 잘 작동시켜야 한다.즉, 미래 보상의 가중치를 즉각 보상 가중 값보다 낮게 설정하는 차감된 보상을 구성하여 항상 제외된 미래 보상이 최대가 되도록 행동을 선택하는 전략(policy)이 좋은 전략이다.이렇게 공제된 미래 보상인 Q-함수를 정의하고 Q치가 최대의 행동을 선택하는 방식에서 방정식을 만들고 이를 되풀이 돌리고 Q-함수를 계산하면 정책 수립이다.현재 상태와 행동으로 구성된 Q값으로 다음의 상태와 행동 Q값으로 함수를 작성하려고

위와 같이 벨망 방정식(bellman equation)이 만들어진다. 함수를 보면 즉각적인 보상과 다음 상태로 얻는 미래 최대 보상의 합이 Q치가 된다.현재 상태로 추정된 큐치=보상+다음 상태로 추정된 큐 값 이렇게 구성하고 반복하면 큐 함수를 구할 수 있어 컴퓨터에 적용하면 좋지만 환경이 복잡하고 크기가 넓다고 기하 급수적으로 계산 영역이 넓어지고 실제 사용 불가능하다.딥 심리에서는 이런 문제를 해결하기 위해서 Q-Learning을 DQN으로 올렸으나 4개가 추가되는 현실 사용이 가능했다.1)Q-Learning알고리즘에 딥-러닝을 적용 2)CNN기법을 추가 3)경험 리플레이 추가 4)목표 네트워크 분리 딥 마인드는 이에 손질하고 개선하는 결국 알파 바둑을 만들어 신약 연구를 하는 수준으로 향하고 있다.테슬라는 자동 운전에 이 기술을 이용하고 보스턴이다 이나믹스은 로봇에 이 기법을 사용하다. 강화 학습이 이처럼 최근 이슈 기술과 떠오르고 있다. 내용이 길어지는 이쯤에서 마무리, 실제 코딩은 다음 자리에 연기한다.이하에 좋은 참조 사이트가 있다.https://hackernoon.com/mit-6-s094-deep-learning-for-self-driving-cars-2018-lecture-3-notes-deep-reinforcement-learning-fe9a8592e14aBy수수깡